Integration Guide
Best practices and process for no-ETL integration
Introduction
This document provides the guidance to start a successful integration with Kubit's Self-Service Analytics. It covers the different approaches to share your data with Kubit and also how to get your metrics configured properly. It also includes the best practices in data model design and implementation as a reference.
Integration Approaches
1. Data Share
By allowing Kubit to securely access your cloud data warehouse directly, no actual data is copied or transferred between accounts. It doesn’t require any engineering work to create ETL or batch jobs, neither does it take up any extra storage. With this approach, Kubit can deliver instant product insight from the real-time live data based on a Single Source of Truth. Check out the Setup a Data Share page for more details on supported data warehouses and the integration steps for each.
2. Direct Connect
This is a warehouse-native type of integration where Kubit connects directly to your data warehouse through a secure connection. This means you will always have real-time access to your data, full control over it and be able to maintain a Single Source of Truth. Check out the Direct Connect page for more details on supported data warehouses and the integration steps for each.
3. Have your CDP load data directly into Kubit
If you are already collecting data through a Customer Data Platform (CDP) such as Segment, Snowplow, Rudderstack, mParticle, you can configure a Snowflake Destination to a Kubit account to materialize all your analytical data there. In this way Kubit can again cover all the compute and storage costs for the Self-Service Analytics.
Process
- Discuss the project scope with Kubit: use cases, KPIs, metrics and dimensions.
- Average duration 1-2 hours.
- Share access to your data with Kubit through one of the integration approaches.
- Average duration 1 hour - 2 days (This is heavily dependent on the integration method you select.)
- Log into Kubit: integrate Single Sign-on (SSO) or provide a list of users that need access.
- Once data is available you will work with a dedicated Customer Success Manager to ensure all requirements have been met and data is accurate.
About Your Data
Your data should already be stored in data warehouse tables for analytics purposes. They should also be updated frequently to stay live. Here are the key considerations for the integration and some best practices.
Data Model
Data model is sometimes presented as an ER (Entity Relationship) diagram. It captures the relationship between all the entities in your database.
It is not preferred to share schema-less transactional data (i.e. database tables used for serving your users) into the data warehouse for analytics purposes. A star schema is the most recommended pattern for storing analytics data.
- Fact tables: Events, Transactions (e.g. Purchases, Subscriptions)
- Dimension tables: Users, Campaigns, AttributionsBelow is a design sample of the proposed data model.
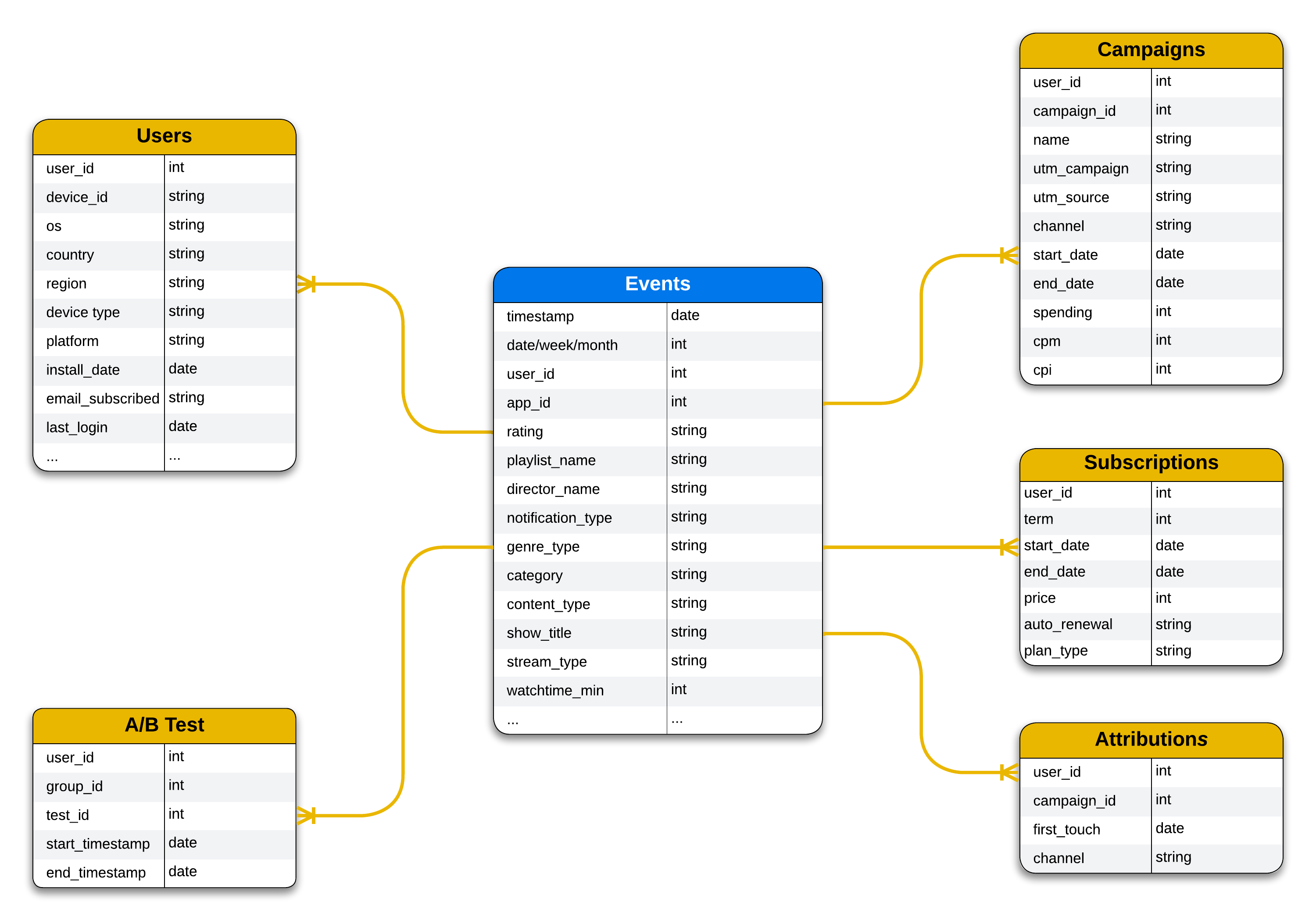
If your current data model is different, don't worry, there are many creative ways to address that by collaborating with your data engineers.”””’
Fact Table Recommendations
The fact tables store information about when something happens (events), some inline properties (e.g. timestamp, country, app_id, app_version), and some dimension keys which can be used to lookup for the dimension values in dimension tables (e.g. user_id to lookup user's email in users table, campaign_id to lookup for a campaign's start and end dates).
In most scenarios, it is recommended to use inline properties on the events as much as possible, i.e. capture most dimensions' values as properties and store them on every event. It simplifies the query and also improves analytics performance dramatically. Modern analytical data warehouses like Snowflake have built-in optimizations to store duplicated column values very efficiently. If you are interested in this topic, read more about columnar database.
Implementation of ETL (Extract, Transform and Load) to populate the star schema from your transactional data is out of the scope for this guide. Though feel free to contact Kubit support to get additional information or advice on this topic.
Recommended Data Structures
User Identification
Every user, regardless of registered or anonymous (guest), requires a unique identifier for the analytics to work. Counting unique users and following a user's behavior (action events) are the most common analytical measures.
User ID 👱Ideally, there should just be one unified identifier field to identify any user. For example, a field
user_idacross different sets of data that you might have.
We understand that User Identification can be complicated because the relationship between a person, different apps, their devices and credentials can be complex. We will work with your team around considerations of privacy, fraud, hacking, device and credential sharing to ensure the best solution is made available. Our flexible data model allows you to be in control of user identity definitions.
Conceptually, there are several IDs:
- Device ID: IDFV or Android ID (deprecated). These identifiers are used to associate a physical device. The use of these is going away because of privacy concerns. In most instances, the Advertiser ID is a value to use.
- User ID: always generate a user identifier as soon as the app is launched so every guest/anonymous user can be identified. This identifier is typically something you will set yourself.
- Account ID: some developers introduce this to identify a registered user across different apps and/or devices. In most cases it brings more pain and confusions. It is recommended to only use it in special cases like analyzing how users use multiple apps on different platforms (iOS, Android and Web). This identifier is typically something you will set yourself.
- Credential (username, email): due to privacy concerns, it is a bad idea to store user credentials in any analytics data.
Events
Events are generated when a certain action takes place. For example: Login, Stream, Vote Up, Page View, Button Click. It is the most critical data structure for analytics.
Data Dictionary
Data Dictionary 📚It is strongly recommended to have a data dictionary (as simple as a Google Sheet) in place to capture the definition of every event.
- Event name: a key (unique short name) and a business name (easy to read and understand).
- Trigger condition: when this event is triggered.
- Properties: the content and meaning of each property stored in this event.
- Owner: who to talk to if a change is needed.
- Version history: what has changed to this event over time. This information is often critical to communicate.
Instrumentation
Events need to be instrumented in the code on both mobile (in the app) and server (backend) sides because some events are triggered by user actions, some by backend processes (e.g. subscription renewal, push notifications sent).
If you are starting from scratch, there is no need to reinvent the wheel. It is recommended to use a CDP (Customer Data Platform) like Segment, Snowplow, Rudderstack, or mParticle, to give you a mature SDK and the maximum flexibility to control where the data goes.
Technology aside, the key of a successful instrument project is communication. Keep in mind that the engineers who are injecting the events into code flow don't usually know how these events are used in analytics. Providing this context information is often critical to avoid bugs and surprises down the line.
Properties
There are two kinds of properties for the events: Common Properties and Event Properties. A property can be categorical (enumeration of values) or numerical (unbounded continuous values).
Recommended Properties
These are the properties that every event should have. Usually they are used in filters or breakdowns as dimension attributes. Here are some examples:
- Timestamp: when an event happens. Sometimes it is necessary to have both Client Timestamp (client clock when action is taken) and Server Timestamp (server clock when the event is processed) since the mobile device clock may not be trusted.
- Date Week, Month, Quarter, Year: It is strongly recommended to also store these parts of the timestamp separately since analytics is often based on these time units.
- Fiscal Quarter, Fiscal Year: only if your organization has the fiscal concept and wants to use them in analytics.
- Device ID: often this is Advertiser ID.
- User ID: the user identifier.
- App: the id or name of the app.
- App Version: the version of the app.
- Country: country where the app is installed (usually from the device).
- Locale: device locale (language + country).
- Gender: user's gender information.
- Birth year: used to compute user age at query time.
- Device model: the model of the device, e.g., iPhone 12 Pro, Pixel 6.
- OS Version: version of the OS on the device, e.g. iOS 13.6.7.
- A/B Test: test id and group assignment of an A/B test.
- Install Date: when the app was installed, used to compute Install Days and group users by how long they have installed the app. It is also critical for Dn/Wn metrics.
Event Properties
Each event can have its own set of properties depending on the context. It is recommended to store them in a set of named generic properties instead of introducing ad-hoc properties on the fly. This way the database table schema can be kept clean and efficient. These generic properties can be explained and managed using Data Dictionary. Here are some examples:
- Context: capture the context information of the event. For example, it can be the flow where the user is in (e.g. Registration, Purchase), or the feature section, e.g., Wishlist, Checkout.
- Target: the target of the event. For example: the content id for a Favorite event; the social channel, e.g., Facebook, or Instagram, for Share event; the SKU for a subscription event.
- Value: the value associated with the event. For example, the price for a Subscription or Purchase event.
- K1, K2, ..., Kn: more named properties slotted for different events.
Timezone
Any timezone conversion during query time will negatively degrade performance.
Performance 🚀For simplicity and efficiency, all the data related to time should be stored as a
timestampordatedata type, which indicates a certain point in time and has no timezone concept.
The complex issue of timezone arises when any date or time is presented in text format, as in every analytics report with dates (MM/DD/YYYY). It is recommended for the organization to decide on using one certain timezone across the board for all analytics purposes. Usually the selected timezone is where the headquarter is based since it is much easier to talk about local dates in business settings.
Define KPIs
This section provides guidance on how to convey your organization's definition on metrics (KPIs) and dimensions.
Metrics
Please provide a list of top metrics for your product analytics needs. Most of these metrics can be presented in simple math formulas with measure functions, along with some filter conditions. For example:
- Engagement: DAU, MAU - unique users in a day or month
- Retention: D2, W2 Retention - % of users who retained (came back) in day 2 or week 2
- Activity:
Likes / DAU,Shares / DAU,Streams / DAU- count an action event divided by DAU. - Monetization: ARPU, Attach Rate -
AVG(revenue) / DAU, percent of users who subscribed. - Funnel: Registration, Purchase - unique users taking action at each steps of the funnel during a certain time period.
- Performance: Download Failure Rate -
COUNT(failure)/TOTAL(start, fail, cancel, end).
Denominator for your calculations 💡It is always recommended to use daily active users (DAU) or monthly active users (MAU) as the denominator to measure rate instead of absolute volume.
Dimensions
Please provide the definitions of all the dimensions needed in the analytics. Most of these dimensions can come from the event's properties. Some dimensions require joining with dimension tables during query time. Here are the information needed:
- Name: display name of the dimension.
- For inline dimensions:
- Name of the event property.
- For join dimensions:
- Dimension table name.
- Dimension value column: the column on the dimension table to be used for dimension values.
- Join key: event property and dimension table column for join.
- Join condition: inner (only matching rows returns) or outer (for rows without match, use
NULL). - Special join conditions: first touch, last touch, time window.
Cohorts
Cohort is a group of users matching certain criteria. You can define these cohorts to be used for breakdowns in any Report, Prediction and Braze Integration using very similar definitions like a query with measures, filters and conditions. For example:
- New Users:
COUNT(First Launched) = 1in last 7 days. - Frequent Streamers:
COUNT(Stream) > 5in last 1 day. - Whales:
SUM(Revenue on Purchases) > 100in last 30 days.
Security
For a SaaS solution, security is always on top of the priority list at Kubit.
Data Security
- Kubit doesn't store or change your data. You have full control over what data is shared and with what permissions.
- You can avoid exposing the tables or columns which are related to user privacy (like email, username, phone number etc) to Kubit. Analytics are performed over aggregated data instead of every user's private information.
- All network communication goes through the HTTPS encrypted channel, including when Kubit talks to your data warehouse and the analytics web interface in the browser.
- Kubit's cloud infrastructure takes all the necessary steps to enforce data security and isolation, including VPC (Virtual Private Cloud) and encrypted network traffic between all components.
- Strict access control and processes are enforced within Kubit organizations to limit and monitor employees who have access to customer data.
User Management
Kubit utilizes Auth0, the leading Enterprise Authentication and Authorization Platform to handle all user security and management.
If your organization is using enterprise user identity services like Google G-Suite, Active Directory or LDAP already, Single Sign-On can be enabled with Kubit through AWS Cognito. There are no extra credentials for users to remember and your IT department has full control over who has access to Kubit.
To start simple, you can also just provide several users' email addresses to get them provisioned on Kubit directly. They can login to Kubit with email and password. Also MFA (Multi-Factor Authentication) can be enabled for these users too to add more security.
Updated 5 months ago